
Idea
The idea was inspired by Ziva Dynamics work to reduce the complexity of film rigs i.e. bones influence and deformation but maintaining the same visual quality
Use cases:
- Realtime rendering
- Procedural animation
- Smaller scene size
- Faster loading, less computation
- To be able to run on low-end systems i.e. Mobile phones
Solution
The solution to this problem was suggested by Bailey in the Fast and Deep Deformation Approximation paper.
The main idea of the paper was to learn from the target rig and approximate vertex positions in your current rig.
The paper explains the following concepts:
- One neuron per Joint
- Hidden layer of neuron where each neuron influence each other result
- Input is multiple sample of joints transformation
- Network will be created based on above input
- The above network is then trained
- And result is the predicted vertex position

Implementation
We need the following software and tools to implement this paper:
- Tensorflow, machine learning library
- Maya 2022, supports for python3
- Google Colab to train on cloud
- Film rig to work on
Algorithm
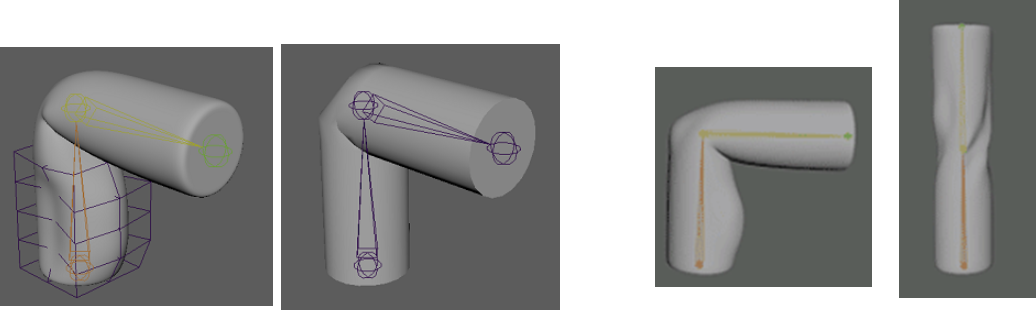
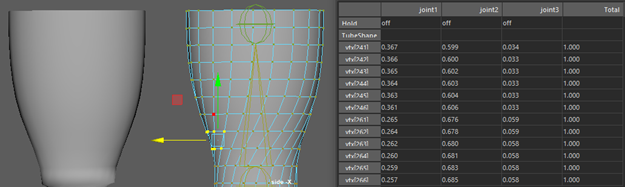
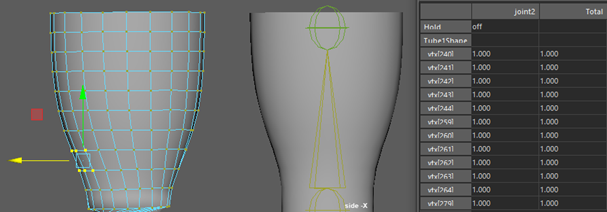
- Make a copy of the target rig with only one vertex influence per joint
- For each frame of sample animation
a.For each vertex, make a record on how far it is as compared to where it is meant to be in the target rig
b.For each joint, make a record of rotation and translation values - Data for training: a & b
- Model is trained: Guess correct vertex offset values
- Move vertices to the correct positions
Implementation in Maya
- Duplicate target rig and simplify weights
- Generate input (joints transform and vertex offsets)
- Train input model in Google Collab
- Create a deformer to view predicted values
Step 1:
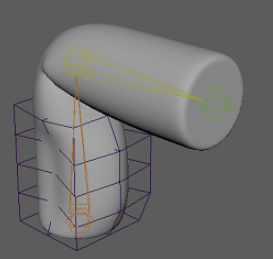
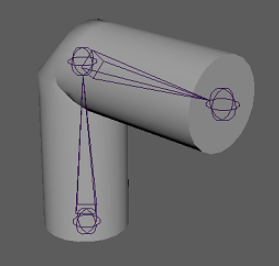
Duplicate target rig and simplify weights
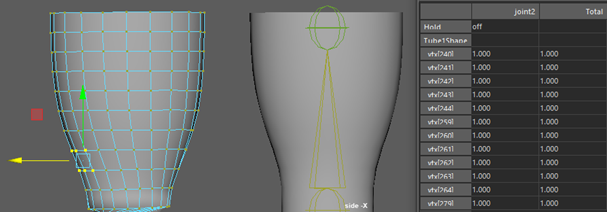
Step 2
Generate input (joints transform and vertex offsets)
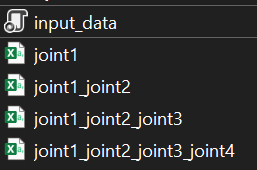

Step 3
Train input model in Google Collab
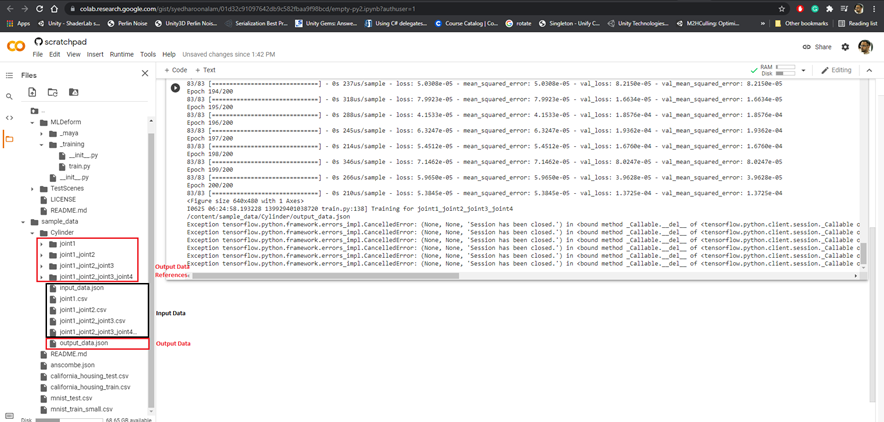
Step 4
Create a deformer to view predicted values
Contributions are welcome:
https://github.com/syedharoonalam/MLDeform
Credits:
https://github.com/dgovil/MLDeform
http://graphics.berkeley.edu/papers/Bailey-FDD-2018-08/
